Le lettere che compongono l’epistolario édito di Italo Svevo costituiscono un corpus di 894 documenti scritti in 7 lingue (italiano, inglese, francese, tedesco, dialetto triestino, russo e latino) e comprende 52 corrispondenti
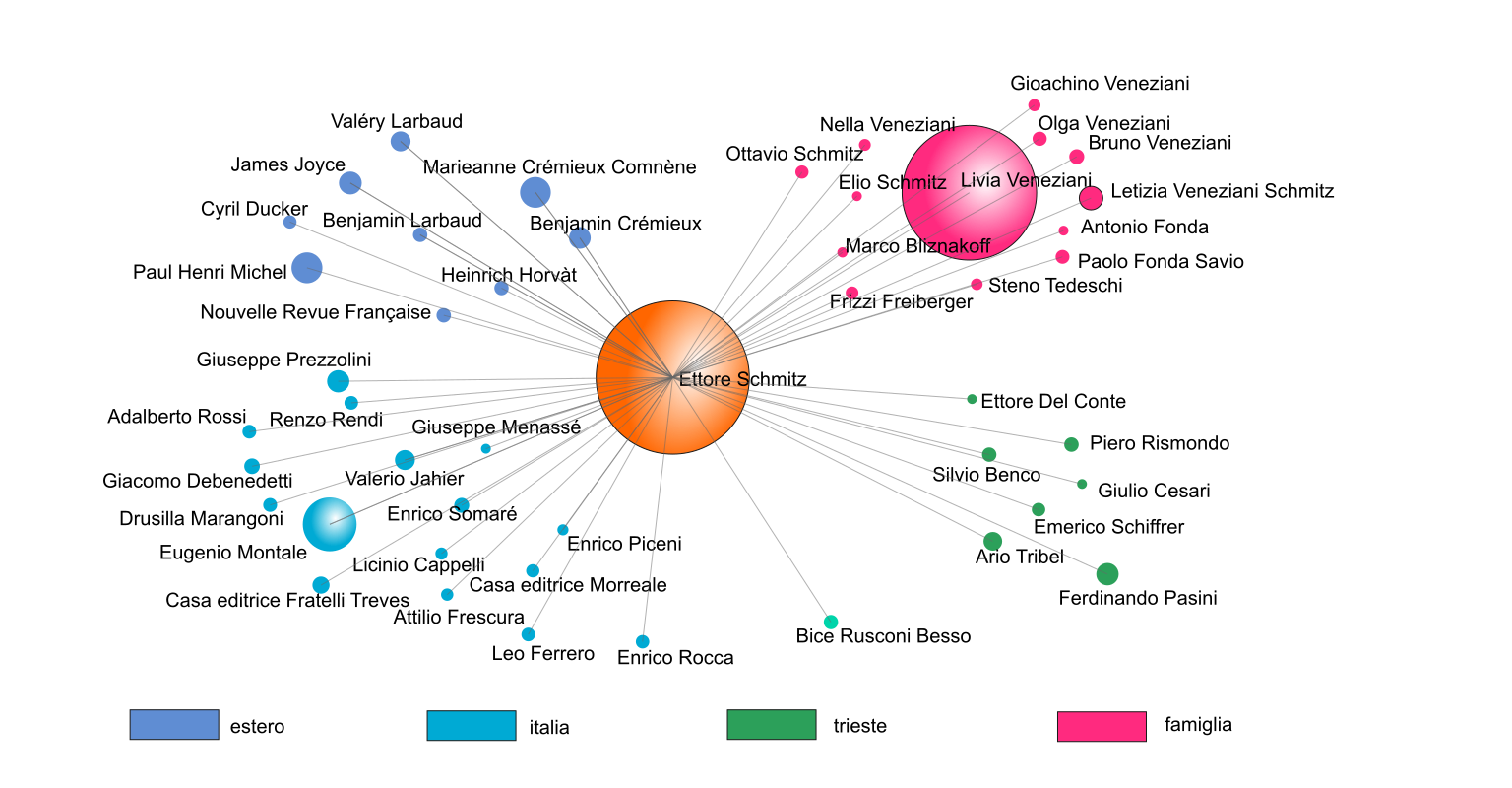
Dal punto di vista delle finalità della scienza dei big data, si tratta di un corpus davvero minimo.
Tuttavia lo scopo del lavoro non è una sperimentazione spinta di Sentiment Analysis su testi d’autore, né tantomeno la definizione di un lessico italiano letterario per la Sentiment Analysis, ma rendere visuale il sentiment del carteggio sveviano per poi rilevare, lungo la linea del tempo tratteggiata dalla produzione letteraria dello scrittore, l’andamento del sentiment di un autore che si è sentito fallito. Una semplificazione qualitativa tradotta in immagini, una resa visuale che fornisce un punto di accesso diverso ai testi delle lettere, anticipandone e corroborandone il senso.
Il file di testo contenente l’intero epistolario édito di Italo Svevo è stato importato in forma di tabella csv – suddivisa in 12 variabili e 894 osservazioni – in ambiente di lavoro “R Studio” per sottoporre i testi dell’epistolario a analisi statistiche tramite software “R”, un tool di analisi statistica open source.
L’approccio a un archivio d’autore ha orientato la scelta di Syuzhet Package – una delle librerie disponibili in ambiente “R” – tarata specificatamente dal suo creatore Matthew Jockers per l’analisi di testi e plot narrativi tramite la rilevazione di picchi emotivi nella scrittura. Syuzhet Package comprende il lessico NRC National Research Council Canada Word-Emotion Association Lexicon (EmoLex), oltre 14.000 lemmi associati a otto emozioni-base (rabbia, paura, aspettativa, fiducia, sorpresa, tristezza, gioia, disgusto) pertinenti la polarità sentiment positivo/negativo. Da luglio 2015 EmoLex è stato implementato con un lessico plurilingue che consiste nella traduzione del vocabolario inglese in una ventina di idiomi tramite algoritmo Google Translate.
Per poter sperimentare un primo utilizzo della versione multilingue di EmoLex, lo staff del MaLeLab di Trieste ha realizzato un’estensione di Syuzhet Package da un codice suggerito da Jockers; è stato così possibile estrarre i valori di sentiment connotanti ciascuna delle 894 lettere dell’epistolario sveviano per le otto emozioni-base, ciascuna validata per lingua e verificare, in seguito, come la qualità dei risultati della Sentiment Analysis può venir influenzata effettuando il preprocessamento del testo noto come stemming, che consiste nel ricondurre ogni parola alla sua radice morfologica, deprivandola quindi del suffisso di declinazione e coniugazione.
Con questo approccio, il punteggio associato ad ogni emozione in una lettera corrisponde al numero di parole presenti nel testo associate alla suddetta emozione.